

We've been running Microsoft Orleans in Kubernetes for nearly 2 years, and for the last half year or so we've had full continuous delivery whenever we commit to master branch in GitHub.
On GitHub there is an issue to gather details for Orleans production usage, and recently k8s popped up in the chat for the latest virtual meetup. A safe and sound deployment regime is the basis for running Orleans in production, so documenting how we do this will be my first contribution. How we do our deploys will touch base on multiple subjects, such as state versioning, testing, feature toggles and metrics. In this blog post I will give an introduction to our application , continuous delivery pipeline and how we deploy to Azure Kubernetes Service (AKS) without downtime.
Deployables
Our application consists of 3 deployables, an API running together with Orleans (the direct client is quite a bit faster), a service processing write messages from the API and another service processing messages from our internal systems. From deployment perspective and important detail is the use of Azure Service Bus
Users perform both read and write operations using the API, all writes goes through Azure Service Bus before being picked up and persisted (we're considering writing directly by default and only use Service Bus in case of write failuers).
We do not use the Orleans.Clustering.Kubernetes provider, we use AzureStorageClustering. The clustering provider is just for reading and writing cluster information. It is not related to the actual hosting model.z
Deployment pipeline
The deploy pipeline is rather straing forward, and fully automated from the point a pull request is merged to master. The deployment will go through two environemnts before our production environment. The first environment we deploy to, stage, has data we can modify to provoke failures. The next environment is our pre-production where data is replicated from our production environment at regular intervals. Finally we have our production environment. We currently run in one data center only as the service provides added value, not primary functionality.
- When something is comitted to master, TC will trigger a build using our docker build container
- TC will run unit and integration tests
- TC will upload the 3 images to Azure Container Registry
- TC will upload a support package to octopus which contains our deploymen script, config file templates ++
- Octopus will create deployment started annotations in Application Insights
- Octopus deploy will execute the deployment script against Kubernetes
- After deployment Octopus wil create annotations in Application Insights and notify on slack
The deployment
Orleans supports blue green deployments, with multiple versions of the same grain type, given the interfaces is versioned as well as versioning state if need. See the Orleans documentation here. I've written about our state versioning technique in a separate blog post.
When deploying Orleans to Kubernetes I would either go for a single StatefulSet or multiple deployments. We chose the latter as we also version our Service Bus topics. Note that both methods will require that
When we start rolling our a deployment we place an annotation in Applications Insights, making it easy to correlate any anomalies with the deployments. The deploymen also contains a link to our internal release note which has a list of all pull requests since the previous version.
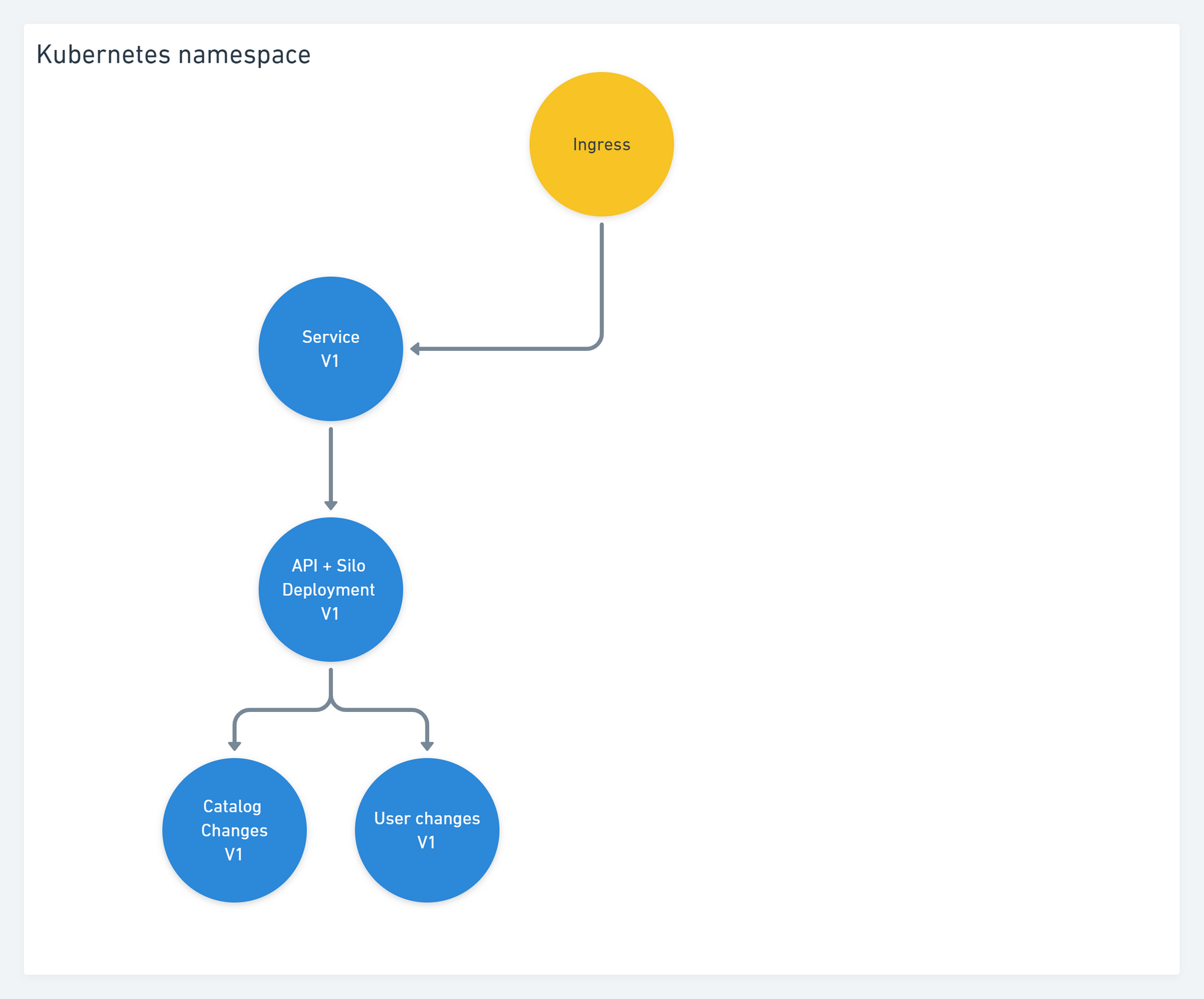
Before the deployment we have a service and the apps in V1, and an ingress which we'll reuse.
During deloy we add the new version and a new temporary ingress for smoke tests. The tests verify that our api respons as expected. Note the dashed line in the diagram below, once the new silos are in the cluster they will start recieving traffic. Also, we have some stateless grains, which read their data from a stateful grain, chances are our tests will hit stateless grains in the new slio which will load its data from v1 grains, not v2. If we were to verify this as well we would need to shutdown both versions, and fire up v2 alone. This is not something we can do in production, but it is possible in other environments.
When we're satisfied with our tests we'll delete the smoke test ingress, switch the old ingress from v1 to v2. We'll then start shutting down the old silos by reducing the replica count 1 by 1, waiting between each one until it is unloaded before shutting down the next one.
We finish off the deployment by placing a deployment completed marker in Application insights
Failures
On the off chance our smoke tests fails we start taking down the new silos one by one. This goes without any serious problems in production as we have already rolled out through 2 other environments (we've had to wipe staging a few times)
Do you ever have to do a full shutdown during deploy?
Yes, we have one grain where we did not bother versioning the state. It means that whenever we change this grain we have to stop all silos and spin up the new ones, resulting in downtime. This is automated in our deploy script, and is based on a label on the pull requests in github. We should propably start versioning that state as well to get out of it. The other case we have seen is when we have incompatibilities in the request context, causing everything to blow up.
What could be better?
Both the warmup and shutdown of silos perhaps. It would be nice to have a silo join the cluster, and only have specific grains/calls to it. Just to keep it free from production traffic on it before our smoke tests are done. Same goes for shutdown, when our tests are fine I would very much like the existing silos to "empty" themself of grains before shutting down and not recieving any new activations. It probably works like this already, but we do see a handful of exceptions during shutdown and it would be nice to be able to do shutdowns without any exception entries in our logs. I have thought about writing a custom placement director to do this, but so far it is just a thought.